Project Brief
Product Information Management Tool and Data Editor Platform – Case Study
By Toby Crome
Head of R&D/Project Management
Paramet Ltd.
Introduction
For the particular product in question, it is useful to break down exactly what the program does by looking at the two main parts that define it. The first part is the PIM, or Product Information Management tool. Put simply, this acts as the single source of truth for product data. It enables the client to bring product information together into one managed location rather than relying on multiple databases, spreadsheets, supplier files and catalogues.
The second part is the Data Editor. This is the area of the system that allows users to make practical changes to the data and carry those changes through into the database. In this case, the Data Editor acts as the bridge between the master product data and the client-specific data requirements, allowing the business to adjust information for customers or deployments without undermining the integrity of the core PIM data.
For businesses managing large or constantly changing product ranges, this type of platform can significantly improve internal processes. It reduces administrative time, improves data accuracy and gives teams a more reliable way of handling product launches, updates and revisions. In the case of this project, the final solution gave the company a more controlled way to manage deployments and product updates whilst allowing greater focus to be placed on the accuracy and completeness of product information.
The Business Challenge
With regards to the challenges that the business faced, the need for the platform can be broken down into several key areas.
Disconnected Data Sources
The company had accumulated product data over the course of many years, with different departments responsible for maintaining information within separate systems. As a result, product information became fragmented across the organisation. When a product needed to be updated, staff often had to manually locate information from multiple sources before they could make a change with confidence.
This prevented the business from having a clear single source of truth and created unnecessary time loss as users searched for the correct master information. It also increased the likelihood of inconsistencies being reported back to the business, particularly where different teams were relying on different versions of the same product data.
Poor Data Quality
As product information was maintained in multiple locations, data quality deteriorated over time. This was often due to partial updates being made in one area of the business without the same changes being reflected elsewhere. Over time, this made it difficult to determine which version of the information was current or reliable.
This left the client with gaps in product records, including missing datasheet information, incomplete graph values and missing technical or acoustic data. These were not simply presentation issues, as the accuracy of this information had a direct impact on product selection, documentation and customer confidence.
Slow Product Onboarding
The previous process for onboarding new products was heavily manual. Engineering teams would receive supplier specifications, which then had to be manually entered into spreadsheets. Marketing teams would then prepare descriptions, images would be uploaded separately, sales information would be updated in another system and website administrators would create the relevant product pages.
This created a difficult and staggered launch process. New products could not always be deployed as quickly as required, and even small changes to an existing product could result in a chain of manual updates across multiple departments and systems.
The Project Objectives
Based on the issues identified during discovery, the project objectives were shaped around improving control, accuracy and speed. The intention was not simply to create another database, but to give the client a practical working platform that could be used by the teams responsible for managing product information day to day.
Centralise Product Data
One of the first objectives was to remove the reliance on scattered sources of information. The client needed a single location where product specifications, technical information, documentation and marketing content could be maintained. This ensured that users were working from the same data, rather than relying on separate departmental copies that could become outdated.
Improve Data Governance
The client also required greater visibility over how product information was created and changed. Existing processes made it difficult to understand who had amended data, whether a change had been reviewed or whether the information was ready to be published. For this reason, validation rules, approval processes and change tracking were identified as important objectives from the outset.
Accelerate Product Creation
A further objective was to reduce the amount of manual administration required when creating or updating products. The client needed a faster way to bring new ranges into the system, particularly where supplier data was already available but required cleaning, mapping or review before it could be used. Bulk editing, configurable templates and import tools were therefore prioritised as part of the project.
Increase Data Accuracy
The fragmented nature of the existing process meant that product data could easily drift between systems. A key objective was therefore to improve the accuracy and consistency of product specifications, performance data, imagery and supporting documentation. This required the platform to enforce standard structures and highlight missing or invalid information before it reached customer-facing channels.
Support Business Growth
As the product catalogue continued to grow, the client needed a system that could scale without requiring a proportional increase in administrative work. The platform therefore needed to support larger product ranges, more complex product structures and future integrations whilst remaining manageable for the teams using it.
The Solution
During the discovery phase, it became clear that the existing approach to product management could not scale effectively. Product information was fragmented, different departments had developed their own ways of maintaining data and there was no reliable mechanism for controlling how changes moved through the business. The decision was therefore taken to develop a bespoke Product Information Management and Data Editor platform that could act as a central source of truth whilst still reflecting the client’s existing workflows.
The solution was designed to give users a controlled but practical way to manage product information. Rather than forcing every user into a rigid form-based process, the platform allowed product data, technical attributes, assets and supporting information to be maintained in a structured environment that could be extended as requirements changed.
Product Management
One of the earliest design considerations was how products should be represented within the platform. Some products contained only a small amount of information, whilst others required detailed specifications, supporting documentation, variants and historical revisions. The resulting product management framework was therefore built to support a wide range of product structures without requiring users to manage each product in a completely different way.
Attribute Management
During planning, it became apparent that a fixed set of product fields would not be suitable. Different product categories required different types of information, and showing every possible field to every user would have made the system difficult to use. A flexible attribute model was therefore introduced, allowing relevant fields to be presented based on the product type, category or manufacturer.
Taxonomy Management
Another issue identified early on was that products were not always categorised consistently across the business. To address this, the platform introduced configurable taxonomy management, allowing products to be organised into categories, families and collections. This gave the client a clearer structure for managing a growing catalogue and made it easier for users to locate related products.
Digital Asset Management
Prior to the project, supporting files such as product images, datasheets and certificates could be difficult to track, particularly where they were stored separately from the product records themselves. The new platform addressed this by linking digital assets directly to the relevant products, helping users find the correct supporting material and reducing the risk of outdated documents being used.
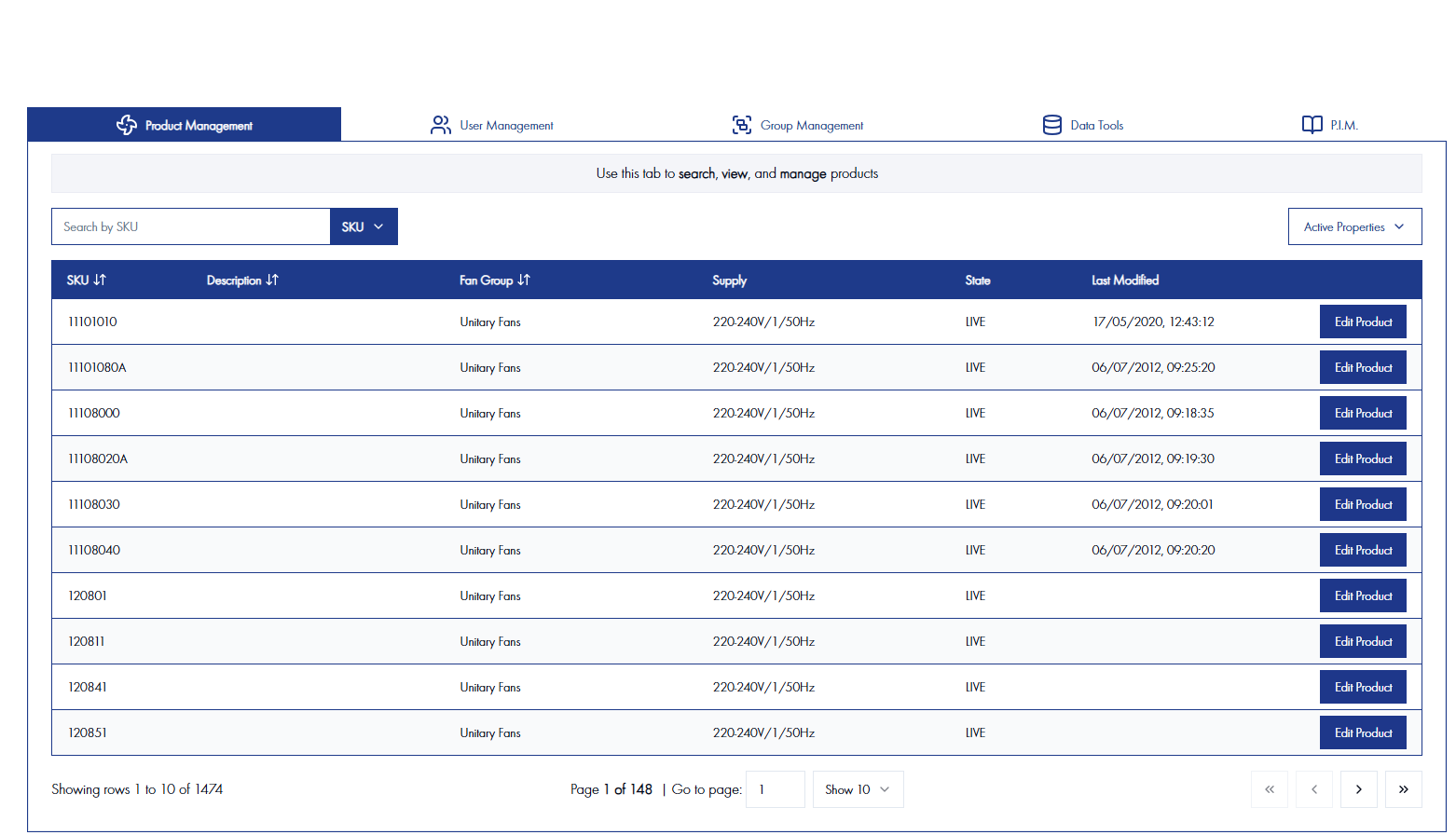
The Data Editor
A key part of the solution was the Data Editor, which was developed to deal with the practical reality of maintaining large volumes of product information. During discovery, it was clear that users were already comfortable working with spreadsheet-style data, particularly when making changes across many products at once. The challenge was to retain that familiarity whilst introducing better validation, governance and database control.
Spreadsheet-Like Editing Experience
Traditional form-based editors can be effective for individual records, but they become slow when users need to make repetitive updates across hundreds or thousands of products. For that reason, the Data Editor was designed around a familiar spreadsheet-like interface. Users could edit information directly within grids, apply changes across multiple records and carry out repetitive updates without needing to open each product individually.
This approach reduced the learning curve because it reflected the way users were already used to working. At the same time, the editor was connected to the underlying data model, meaning changes could still be validated and controlled before being committed.
Bulk Data Operations
A recurring issue with the previous process was the amount of time spent moving data between supplier files, internal spreadsheets and business systems. To address this, the platform included import and export functionality capable of handling common formats such as Excel, CSV, XML and JSON. This allowed legacy data and supplier information to be brought into the platform more efficiently.
Export processes were also developed so that product information could be distributed to other systems and channels in the formats they required. This was important because the PIM was not intended to operate in isolation; it needed to support ERP systems, ecommerce platforms, customer feeds and other downstream processes.
Validation Engine
The introduction of bulk editing created a further challenge. If users could change large volumes of information quickly, the system also needed safeguards to prevent incorrect data from being saved or published. A validation engine was therefore included to check required fields, data types, duplicate records and business-specific rules.
Examples included ensuring product identifiers remained unique, mandatory specifications were completed and numerical values sat within acceptable ranges. These checks helped the client improve data reliability without relying solely on manual review.
Technical Challenges
The development of the PIM and Data Editor presented several technical challenges. These were mainly connected to the complexity of the products being managed, the volume of records involved and the need to standardise data that had originated from a variety of internal and external sources.
Complex Product Structures
Many of the products could not be treated as simple standalone records. Some formed part of larger product families, with variants, configurations, accessories or bundled components. This created a challenge because the system needed to preserve parent-child relationships whilst still allowing users to edit product information efficiently.
To resolve this, a flexible data model was developed that could support hierarchical product structures. This allowed shared information to be managed consistently while still giving individual variants or child products their own specific data where required.
Large Data Volumes
The platform also needed to remain responsive when handling large catalogues. As record counts increase, search, filtering, editing and import operations can become noticeably slower if the data is loaded or processed inefficiently.
Several optimisation techniques were therefore introduced. Product data was indexed to improve search performance, pagination was used to avoid loading unnecessary information, and background processing was used for heavier operations such as imports, exports and large-scale updates. Caching was also applied where repeated lookups could otherwise place unnecessary load on the database.
Data Normalisation
A further technical challenge was the condition of incoming data. Supplier files and legacy records did not always use the same structure, terminology or units of measurement. Manufacturer names, legacy codes and technical values could be represented differently depending on the source.
To address this, the platform used mapping tables, transformation rules and standardisation logic to bring incoming data into a consistent format. This reduced the amount of manual cleansing required and helped ensure that products could be compared and maintained using the same conventions.
User Experience Design
A significant part of the project was ensuring that the system could be used by different teams without becoming overly complex. Product managers, marketing users, technical teams and administrators all needed access to product information, but each group approached the data from a different perspective.
Supporting Different User Types
Product managers needed clear editing tools and a way to move products through approval stages. Marketing teams needed to manage richer content, including descriptions, images and supporting documents. Technical teams required access to detailed specifications and attribute controls, whilst administrators needed oversight of permissions, auditing and governance rules.
Rather than designing the system around one type of user, the platform was structured so that each group could access the areas relevant to their responsibilities. This helped keep the interface practical and reduced the risk of users being overwhelmed by information that did not apply to their role.
Search and Discovery
As the product catalogue grew, finding the right record quickly became just as important as editing it. The platform therefore included global search, filtering and saved search functionality to help users navigate large datasets more effectively.
For more advanced use cases, query-building functionality allowed users to search across multiple product attributes and fields. This was particularly useful where users needed to locate products with specific technical characteristics or identify records that required further attention.
System Integrations
A major challenge throughout the project was ensuring that the new platform could coexist with the client’s wider business systems. Product data already existed in several locations, and replacing every existing process was not practical. The PIM therefore needed to act as the central source of truth whilst exchanging information with the systems that remained in use.
ERP Integration
The client’s operational systems remained responsible for commercial and stock-related information, such as pricing and inventory. The platform was therefore designed to exchange product information with ERP systems rather than duplicate their role. This helped maintain alignment between operational data and the product information managed within the PIM.
Ecommerce Integration
Customer-facing websites and ecommerce platforms depended on accurate product information. By connecting these channels to the PIM, product content, specifications, imagery and documents could be published from a controlled source rather than updated manually in multiple places.
Marketplace and Partner Feeds
The platform also needed to support external sales channels and partner portals. These channels often required product information in different formats, so export and transformation processes were used to prepare data for each destination while still maintaining the PIM as the controlled source.
API Layer
To avoid building the platform as a closed system, an API layer was introduced to allow product information to be exchanged programmatically. This created a more flexible foundation for future integrations and reduced reliance on manual imports and exports where automated synchronisation was more appropriate.
Governance and Compliance
Because product information was used across multiple areas of the business, governance was an important part of the platform. The client needed to know not only what the current data was, but also how it had changed and whether it had been reviewed before being used externally.
Audit Trail
An audit trail was included so that changes to product information could be traced. This allowed users to identify who made a change, what was changed and when it occurred. This was particularly important where product data affected technical documentation, sales information or customer-facing systems.
Approval Workflows
Approval workflows were introduced to reduce the risk of incomplete or incorrect information being published. Product records could move through stages such as draft, review, approved and published, giving the client greater control over when information became available to other systems or users.
Role-Based Security
Different users required different levels of access. The platform therefore included role-based permissions so that users could only access the tools and data relevant to their responsibilities. This helped protect the integrity of the data while still allowing teams to work efficiently.
Key Innovations
Several areas of the project required more than standard data entry functionality. The most useful features were those that directly addressed issues encountered by the client during product maintenance, onboarding and data review.
Intelligent Attribute Management
During early testing, it became clear that users could be overwhelmed if every possible field was displayed at once. The intelligent attribute system addressed this by showing fields based on the type of product being maintained. This reduced clutter in the editor and helped users focus on the information that was actually relevant.
Bulk Data Editing Engine
The bulk editing engine was developed because the client needed to maintain large volumes of product data without opening each record individually. This allowed users to make controlled updates across multiple products while still benefiting from validation and review processes before those changes were committed.
Automated Data Quality Controls
Rather than relying entirely on users to spot incomplete or inconsistent records, the platform introduced automated checks to highlight potential issues. These checks helped identify missing values, duplicate information and data that did not meet expected rules before it affected downstream systems.
Supplier Data Ingestion
Supplier data was often received in formats that did not match the client’s required structure. The supplier ingestion process was therefore designed to map, transform and standardise incoming files so that new products could be created more quickly and with less manual correction.
Results and Outcomes
The implementation of the PIM and Data Editor gave the client a more reliable and scalable way to manage product information. The most immediate benefit was the reduction in manual effort, as tasks that had previously required updates across several systems could now be carried out from a central platform.
Operational Efficiency
Product onboarding and maintenance became more efficient because users no longer needed to repeat the same updates across multiple spreadsheets and systems. The Data Editor allowed large groups of records to be maintained more quickly, while the PIM provided a controlled location for managing the master product information.
Data Quality
The introduction of validation rules and a central data structure improved confidence in the information being used across the business. Missing values, duplicate records and inconsistent specifications could be identified more easily, allowing users to address issues before they were carried into customer-facing systems or documentation.
Commercial Impact
By reducing the time required to prepare and maintain product data, the business was better placed to respond to product changes and launch new ranges. Accurate and consistent product information also improved the experience for customers and internal sales teams, reducing confusion and creating a stronger foundation for future digital growth.
Lessons Learned
Several important lessons emerged during the development and implementation of the platform. The first was that the success of a PIM project depends heavily on data ownership. The software can provide structure and validation, but the business still needs clear responsibility for maintaining and reviewing the information.
Another key lesson was the importance of flexibility. Product data is rarely uniform, and different parts of the business often describe or manage products in different ways. Building a platform that could adapt to these differences was essential.
User adoption was also a major consideration. The Data Editor was successful because it reflected the way users were already used to working, while still introducing stronger controls behind the scenes. Finally, the project reinforced that integration with existing systems is often one of the most complex areas, particularly where legacy processes and data structures need to be preserved.
Future Roadmap
Although the project addressed the client’s immediate requirements, several opportunities for future enhancement were identified. These include AI-assisted product enrichment, automated categorisation, attribute extraction from supplier documentation, supplier self-service portals and further automation around marketplace publishing.
The architecture was designed to allow these capabilities to be introduced over time. By establishing a scalable and extensible foundation, the client is now better positioned to continue improving their product information strategy as the business and its catalogue continue to evolve.



